进阶能力
多角色台词
用 JSON 脚本精确控制每一句台词由谁来说,实现多角色对话、剧本演绎。
基础的 TTS 是"整段文本 + 单个音色"。Speech 多音色脚本则允许精确控制每一句台词由谁来说 — 编排三人辩论、小说对话、教学场景,每个角色有自己的声线和台词。
发起请求
告诉 AI 想测试多音色脚本功能。AI 自动创建一个多角色对话脚本,分配差异化的音色:
- 苏哲(理性男声)— 主持人,负责开场和观点输出
- 若云(温柔女声)— 提问者,负责引出焦虑和推演
- 原野(北京腔男声)— 总结者,负责哲学收束

脚本结构
生成的脚本是一个标准 JSON 文件。每条台词指定 content(台词内容)和 speakerId(音色标识),按数组顺序依次朗读:
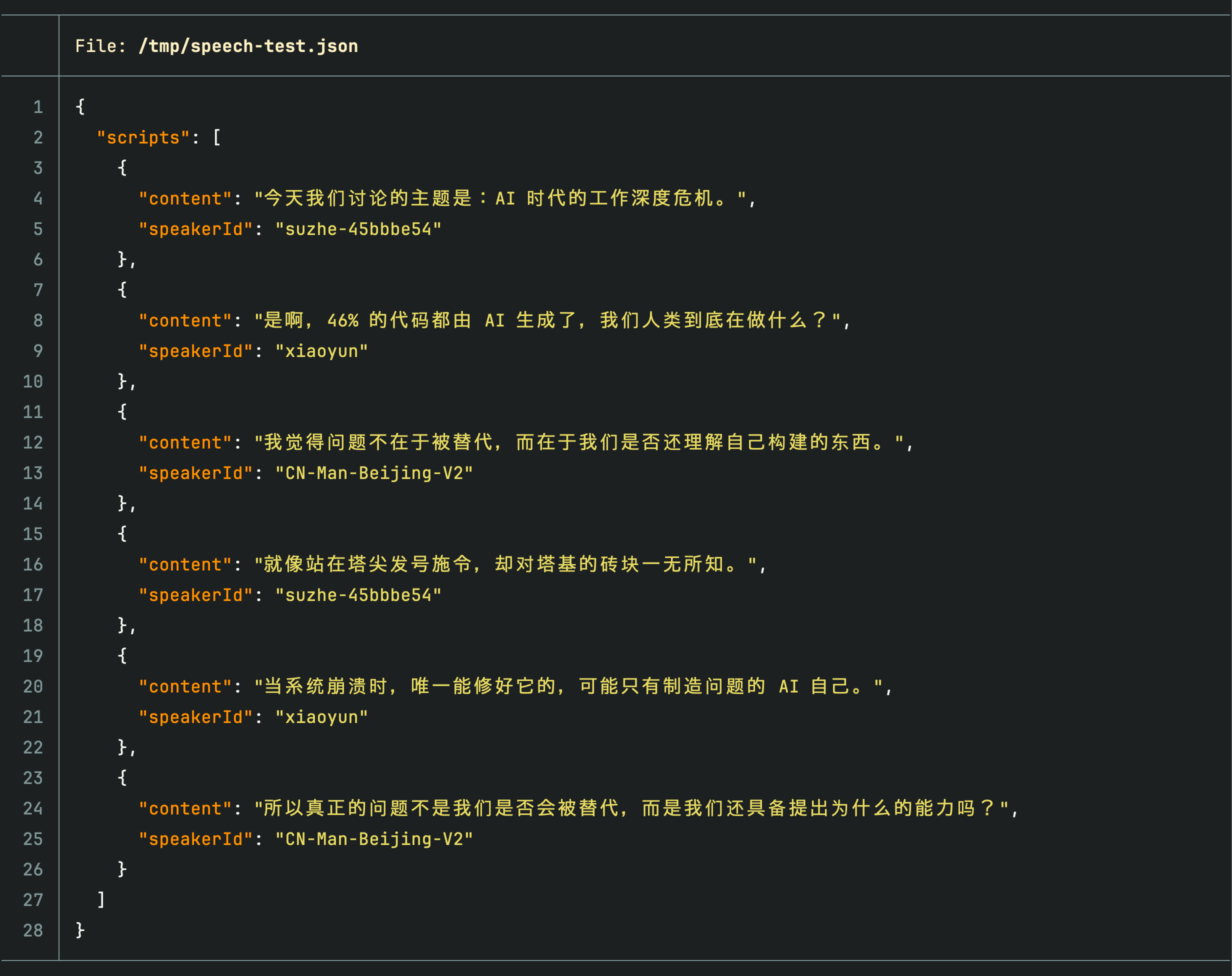
这个结构的意义在于完全可控 — 两个人轮流对话、三人圆桌讨论、一人独白穿插旁白,都可以通过调整 JSON 实现。可以手动编写脚本,也可以让 AI 根据需求自动生成。
多音色对话完成
提交后约 30 秒,三人对话音频生成完成。AI 返回在线收听链接、字幕文件、音色阵容和对话结构:

Speech 与 TTS 的区别
| 特性 | TTS(语音朗读) | Speech(多角色台词) |
|---|---|---|
| 控制粒度 | 整段文本,单个音色 | 逐句控制,多个音色 |
| 适用场景 | 文章朗读、长文本 | 对话、剧本、有声书 |
| 脚本格式 | 纯文本 | JSON(scripts 数组) |
| 编排自由度 | 低 | 高 |